Rate Limiting Saves the (Sun)day
December 29, 2023
TLDR
A spambot spammed our signup endpoint, causing our AWS SES account to be blocked due to a high bounce rate on our signup confirmation emails. I implemented a fixed-window rate limiting middleware in TypeScript for Curveball to prevent the attack from happening again.
This article describes the incident and the implementation of the rate limiter.
We got attacked
It was a lazy autumn Sunday afternoon. As I was walking around in the park, coffee in hand, listening to the singing of the few birds that had not yet realized that a freezing winter was coming, I started receiving complaints that our users were unable to sign up to our application. The users were getting an error message when submitting the signup form - something about emails not being sent.
Starting my spelunking to uncover what might have been causing the signup error message, I discovered that AWS had blocked our SES (Simple Email Service) account on suspicion of spam.
Further investigation into the server logs and AWS dashboard revealed that we had received several thousands of signups within the span of a couple of hours the previous night. Apparently, had signed up to our app roughly 2 seconds after had. Either we were becoming popular among Asia's diplomatic corps and they were all using Gmail, or we were getting spammed with fake signups.
The issue became immediately obvious:
- The attack bot would send a request to our signup endpoint with a fake email address
- Our application would send a confirmation email to the fake email address
- The email would bounce and negatively affect our SES account reputation
- After a few thousands of such bounces in a short period of time, AWS would flag us as spammers and block our SES account
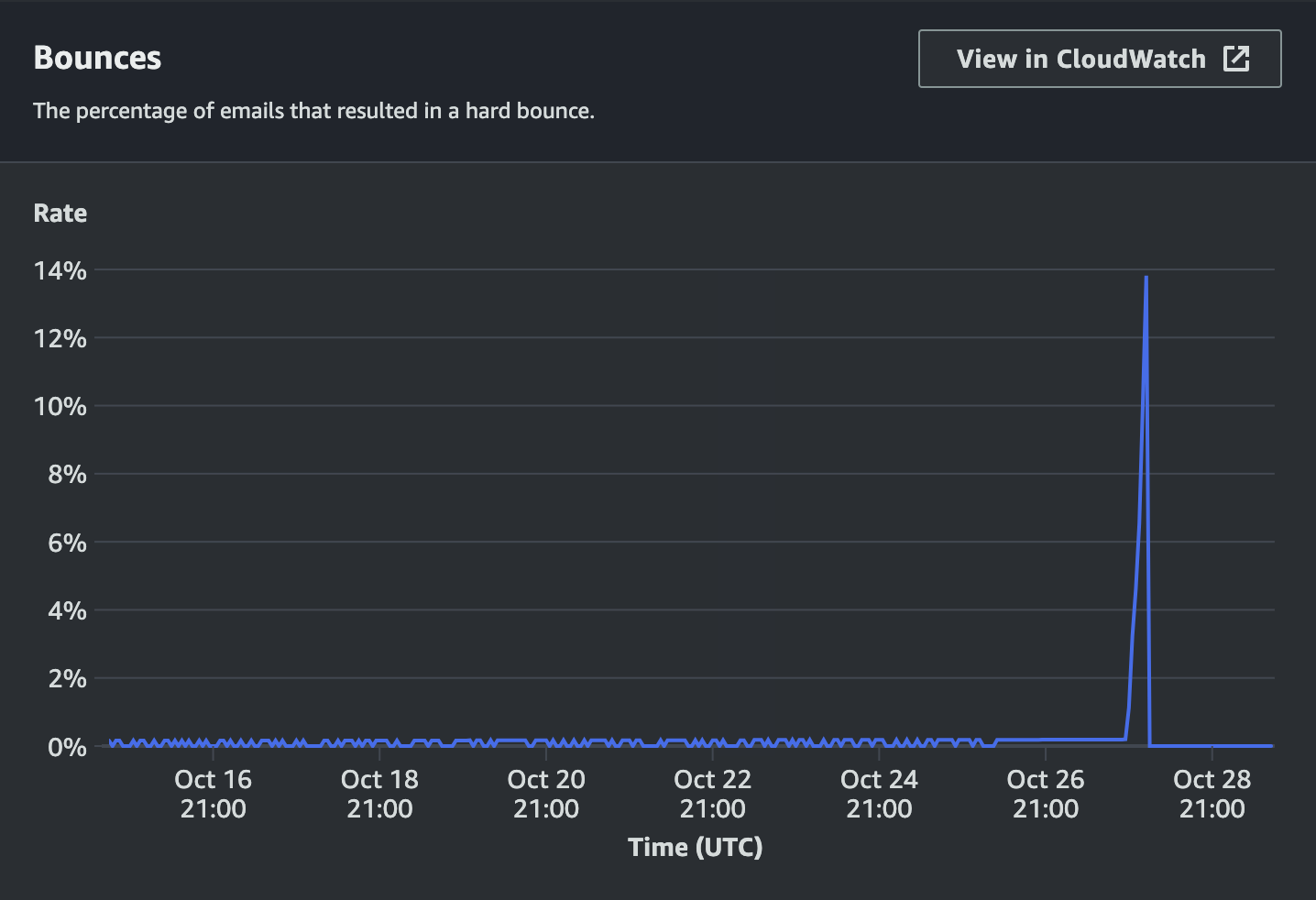
We had not implemented any rate limiting on our signup endpoint, so the bot was able to send as many requests as it wanted. From looking at the logs, it seemed like the bot was sending a request every 1-2 seconds, for several hours.
To resolve the incident and open signups again, we had to take defensive steps to prevent this attack, and ask AWS to unblock our SES account.
As I was sipping my coffee, and now sitting down, slouched forward looking at my phone on the park bench, I started thinking about how to prevent this from happening again. The solution seemed straightforward - implement rate limiting on the signup endpoint and any other endpoint that could be abused in a similar way.
Rate Limiting
Rate limiting is about limiting the number of requests that a user can make within a given time window. For example, you might want to limit the number of requests a user can make to your server to 100 requests per minute. You might go more granular and set up different limits for different endpoints.
In our application, a user realistically does not need to sign up more than once so we decided to limit the number of signups a user could make to 1 signup per 15 minutes. Since users trying to sign up do not yet exist as users in the database and do not have an identifier, we went with the oversimplification that an IP address would uniquely map to an anonymous user.
Limiting the number of signups per IP is not ideal as it can lead to false positives. For example, if Bob and Alice are on the same network in say their office, they will share the same IP address and if Bob signs up, Alice will not be able to sign up until 15 minutes have passed.
But for that lazy Sunday afternoon emergency scenario, it was good enough a solution. We could always go back and implement a more sophisticated solution later.
Where to Implement Rate Limiting
Implementing rate limiting can be done at different levels of the stack. You can implement it at the network level, at the load balancer or API gateway level, or in the application code.
If you have a configurable reverse proxy such as Nginx fronting your application you can implement rate limiting there (see here for an example). In our case, our application server is running on an AWS ECS cluster and is fronted by an AWS Application Load Balancer (ALB) and we do not readily have much control over the ALB configuration.
As I did not have much time to start messing with the infrastructure, I decided to implement it at the application level.
As we have multiple server instances running in our ECS service and we already used Redis for caching, I decided to use Redis as a store for the rate limiter and write a simple middleware that would be running as part of our application server.
Fixed window rate limiting might be good enough
There are many different algorithms for rate limiting. The main ones are fixed-window and sliding-window.
At a high-level, fixed-window rate limiting works by keeping track of the number of requests a user has made within a given slice of time. But it is a bit unsophisticated. For example, if you rate limit a user to 100 requests per minute, and they make 100 requests at 12:59:59, they will be able to make 100 more requests at 13:00:00.
Sliding window rate limiting on the other hand is more granular and more sophisticated. If your user makes 100 requests at 12:59:59, they will not be able to make any more requests until 13:00:59.
I was leaning towards implementing a sliding window rate limiter as it seemed more sophisticated and who does not want to be sophisticated? As I started reading up on sorted sets in Redis and seeing the syntax for the commands, I started to dial back my thirst for bourgeois sophistication and decided that after all, a little rustic simplicity would do.
I just needed to put some basic contingency in place to prevent the attack from happening again, tell AWS I had done it, and go back to enjoying my coffee and the park.
Curveball middleware
We use Curveball - we had the pleasure to work with the maintainers of the project about a year ago. The Curveball framework is similar to Express and Koa. Although the framework is not as popular as Express or Koa, it is a nice framework that is easy to use and extend and works perfectly well with TypeScript without any additional configuration.
A middleware in Curveball is a function that takes a object and a function as arguments. The object contains the request and response objects, and the function is a function that calls the next middleware in the chain.
You can define a middleware like this:
The contrived example middleware above checks if the request method is and throws an error if it is not. If it is, it calls the next middleware in the chain.
The idea then is to chain middleware together to form a pipeline. For example, you can have a middleware that attaches a user object to the context, and then a middleware that checks if the user is authenticated, and then a middleware that checks if the user is authorized to access the resource, and so on.
The final middleware in the chain would typically be the one that sends the business logic response back to the client.
Rate limiter middleware
I knew I wanted the middleware to be somewhat configurable so we could easily use it for different endpoints with different limits. Thinking about it, I figured we would also want to rate limit the endpoint that requests a password reset email and some other ones.
I also wanted to be able to use it for different types of limits - for example, limiting the number of requests per IP address seems sufficient for non-authenticated users, but we might want to limit the number of requests per user (using their as request group) for authenticated users.
Maybe it was the coffee that was making me think big and grandiose, but I wanted to not only roll out that yet-to-be-written middleware for our signup endpoint within the next hour or two, I was also starting to think I would then release it as a library on .
I could already feel it. The fame, the glory, the adoration of the masses. I was going to be the next open source software pioneer. I was going to be the next Linus Torvalds. The success at my fingertips was already getting to my head.
Shaking with excitement, I started thinking about the API for the middleware. I wanted to be able to do something like this:
The middleware would take a configuration object with the following properties:
- : The path of the endpoint to rate limit
- : The HTTP method of the endpoint to rate limit
- : The number of requests allowed within the given window of time
- : The window in milliseconds within which the number of requests is limited
- : The store driver to use for storing the number of requests (Redis in our case, but could be anything that implements some yet-to-define interface)
- : A callback function that has access to the request context and returns a string that is used to map requests together (for example, returning the IP address of the user to limit the number of requests per IP address)
The middleware would then keep track of the number of requests made within the given window of time and send a response if the limit is exceeded, along with a header that indicates how long the user should wait before making another request.
The header is optional, but it is a good practice to include it as it allows the client to know how long to wait before making another request and possibly communicate that to the user in the UI. If you remember the oversimplification I mentioned earlier where we were using the IP address as the identifier for the user, the header would allow us to tell the user that they can try again in minutes and confusion would at least be mitigated.
The store
The store is the driver called to persist the state of the rate limiter. In this case, the state is the number of requests made by a user within a given window of time.
Since I was going for a fixed window rate limiter, the middleware state only needed to keep track of the number of requests made for the current window of time. It did not need to keep granular track of the time at which each request was made.
As such, all we needed here was a simple key-value store where the key would be the identifier of the user's window (for example, the IP address concatenated with a specific timestamp or time window id) and the value would be the number of requests made by that user in that window.
We also needed to be able to set an expiration time on the key so that the store driver would automatically delete the whole window when a new window would start.
I defined the interface as follows:
I then implemented a Redis store driver that implements the interface:
The store driver takes an instance of and uses it to increment the value stored at the key by 1 and set the expiration time. It then returns the value stored at the key.
That's it.
We instantiate the store driver like this, where the application is getting bootstrapped:
If you are unfamiliar with the pattern used here where we pass in the store driver into the , it is called dependency injection.
It makes the class more flexible and easier to test - this is how we can easily mock the store implementation in our tests or leave it up to the user of the middleware to decide which store driver to use and create their own if they so desire.
We can also easily swap out the store driver implementation if we decide to use some other persistence store in the future (e.g. memory store, postgres, etc.).
The middleware logic
Then for the middleware logic, we use the store driver to increment the value stored at the key and check if it exceeds the limit. If it does, we send a response, if it does not, we let the request move on to the next middleware in the chain.
There you have it. A basic fix-window rate limiter middleware that uses Redis as a store.
In the application server, we then define a per-endpoint ruleset and pass it to the middleware:
As the sun sets
I was able to roll out the middleware to production within a couple of hours. I then added a Captcha to the signup form and asked AWS to unblock our SES account.
Signups were open again.
What had started a lazy Sunday afternoon had turned into a busy Sunday evening.