Building a hierarchical geo search for remote jobs
March 7, 2022
In this article, we discuss the database design for a feature similar to LinkedIn's remote job hierarchical geo-search where the search results show you jobs open to candidates from any parent geographical unit.

LinkedIn's Remote Job Search
LinkedIn is one of the few websites, if not the only one that does remote job search right. They do not treat locations as mere keywords and do not treat remoteness as just an extra tag.
If you've made a search for remote jobs on LinkedIn recently, you might have noticed that the same jobs show up in search results for different locations. Take the following search result for that shows up for both Tokyo and Singapore as an example:
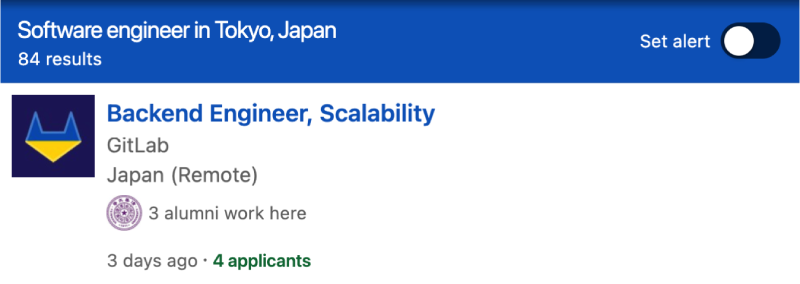
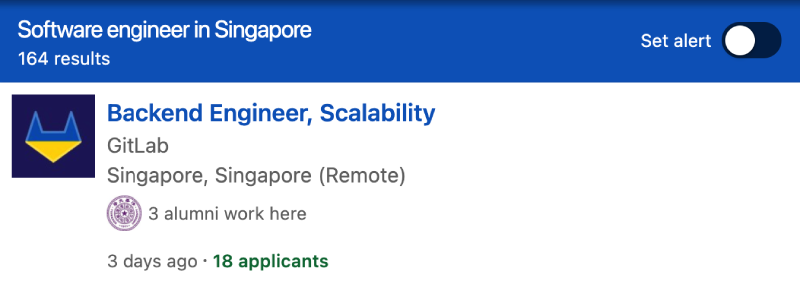
What is happening here is that LinkedIn returns all the jobs that can be done from that georgaphical location. In this example, GitLab must have posted the job as being open to candidates in Tokyo, Japan or in Singapore. The company may also have opened the job to applicants located in one of the parent locations of Tokyo and Singapore - such as Asia or the world.
Let's see how we could build a similar search experience. As a disclaimer, I do not work at LinkedIn and have no idea how they have actually implemented this feature.
A graph problem
Search as a graph problem
The first observation we need to make here is that searching for geographically-constrained remote jobs is a graph problem.
The world can be represented as a tree of administrative divisions where the entire planet (or !) is the root, every continent is another layer of nodes, every country is another layer, etc.
We could represent the world as a topological tree made up of continents, countries, national administrative subdivisions, neighborhoods, streets and addresses:
This is a legitimate way of representing the world, but might be a bit too restrictive for a relatively exploratory search. The world is often a bit more ambiguous and complex than that. Continents are mostly abstract concepts that are at least somewhat subjective. Some groups of geographical places span multiple continents and countries
Take Russia for example. It is both in Europe and in Asia. The Middle East which is a region that is ambiguously located at the junction of multiple continents. Latin America may include Mexico, which is in North America.
The hierarchical nature of a structured tree may not apply perfectly here. A graph might be a better suited data structure.
Graph or tree
Why do we even care whether the world is a tree or a graph?
We care here because people may want to search for jobs available in certain abstract regions rather than in neatly defined administrative boundaries. By squeezing our problem into a tree problem, we force every geographical area to be connected to only one parent node.
If we go with a more arbitrary graph, we can have many paths to a node. This opens the possibility to search the geographical graph in more exploratory ways than through the strict tree topology.
For example, we could search for anything located in any constituent part of a free trade zone or some geopolotical group. We could find all locations in Asia, including fine-grained locations located within the Asian part of Russia - instead of forcing Russia to be all in Europe or all in Asia.
Using a tree (meh idea)
We could emulate the same idea with our tree, but that would be much less elegant and kind of a "when a hammer is all you got" type of a situation.
You would essentially end up with something like this:

Here's what this horror is:
- each place has a single path from the root and we have a clean tree
- to represent arbitrary groups of nodes that span multiple subtrees, we maintain some sort of a structure that looks like:
- when making a search for an entire group, we would need to do some kind of a or simulate one (through denormalization, refs or other tricks) to first retrieve the constituent paths and then retrieve the descendants or ascendants of these paths
If you were to design a schema for this horror in a SQL database, you would have something like this:
Now let's say you've got a defined for and connects it up to the nodes via the closure table. Now let's say you want to connect a remote job to that zone; you would have two ways:
-
You either turn into on insert. In your application code, you get the user input for the area they want to make their job available in, say . You look up that in your table, retrieve all the s; then you connect the job that is being posted to every one of these jobs.
-
You go polymorphic with something like or ; and you add even more complexity to something that is already likely to be quite complex.
Probably a bad idea to force the problem into a tree.
SQL or NoSQL?
By the way, haven't covered that just yet. So far we assume that you are using a relational database, but complex search (requiring facets and whatnot) is often a better idea to build in a NoSQL system.
Complex search is especially suited for a search engine like ElasticSearch or even a SaaS such as Algolia or Meilisearch.
This is an implementation detail as far as this article goes. NoSQL systems typically recommend storing trees using materialized paths - which is the same idea as the in PostgreSQL. Materialized paths to an extent are already a form of data denormalization.
Using a graph (better idea)
Hope you have been convinced that modeling the search space as a tree is probably not such a great idea. So let's see how we would model the issue as a graph - which will still look very much like a tree.
Now when we model our search as a graph search, we can have multiple paths to each node - i.e. nodes may have more than one parent or rather neighbor connected via a edge.
For example, Mexico could have two different paths from root to itself because it can belong to both and :
- Latin-America is represented as just another location node in our graph
- Mexico:
- when making a search for , we would just need to match the path to retrieve the result set that contains the Mexico node

This is a much more natural way of modeling our data. It is also more flexible as we could add new nodes easily without having to rework definitions as in the previous example.
In terms of relational schema, you would end up with something like this:
The ltree-based search would then happen on the closure table () like so:
Cardinal sin: Driving the point home
If you are still unconvinced that the world is not a tree, let's drive the point home here by showing how you could model this in a NoSQL denormalized way.
If you go with the tree design, you would likely have the following collections (MongoDB) or indexes (ElasticSearch):
Documents in the collection would look like this:
Your collection would look something like this:
Note a giant problem so far because our is limited to coarse locations at the level.
Now consider this scenario: you have decided to put under because after all, its major cities are in Europe. But then you realize that people exploring the path won't see any result associated with because this country is not in this subtree.
You decide that the best way of solving this is to create a containing every location actually inside :
Notice the issue? Zones might end up blowing up into infinitely growing arrays, especially if you have to go granular. This means you would need to do some expensive operation (distributed NoSQL databases are not great for that) or retrieve the in the application code and fire a bunch of queries or a massive type of boolean query to retrieve all the locations that match the s for that .
The graph way of modeling the problem turns the design around a bit as you would have multiple paths per ; so you would not need a separate lookup collection. You could just have one collection that looks like this:
The cardinality of should be much lower than the cardinality of because any location can only be part of so many supranational aggregates. If you index the , having such an array of only say a couple of hundreds would not be much of an issue.
What about the jobs?
So far, I've only talked about how you would model the geographical data to enable graph traversals, but I have not really covered how that even relates to LinkedIn's remote job search feature.
We can try to pseudo-formalize the search problem as follows:
- A search for remote jobs in location returns remote jobs open to applicants located in or any one of ; where .
This means that the first step is to locate all the nodes that are relevant to the user search query.
Relational model
Again, probably not the best idea to build a complex search system on a relational database. Faceted search and other such features get tricky to implement and can easily devolve into Entity-Attribute-Value (EAV), which is notoriously difficult to maintain and work with due to the level of indirection it introduces.
You could go with something like this:
Let's walk through an example:
- User is searching for jobs in
- Get the for - something like
- with the table to get all the ancestors (and self) to all of these paths - i.e.
- with the table to retrieve the s for these nodes
- with the table and filter remaining attributes of the jobs
- with the table to get all the relevant jobs
That's it, you've traversed your graph and filtered out the results you do not want, sort that set by date (or whatever else) and return that.
If performance is not a concern, you might be able to get away with just stuffing the job description into a column, especially if there are only a few thousands jobs on the website. One should note that this is rather sacrilegious practice though, but then again, EAV kinda is too.
If query complexity gets out of hands, redis and a CDN should go a long way in saving some load off your database server. Given the nature of the data, you'd have mostly cache hits.
NoSQL model
ElasticSearch would be a perfect candidate for complex search, we could easily index materialized paths for each of our locations. MongoDB allows for the same kind of modeling although I am less familiar with how it indexes array values internally.
If you are using ElasticSearch, there is a path_hierarchy tokenizer you can use to split up your materialized paths.
We could have two collections:
- - the location nodes in our graph
- - the jobs
Your collection could look something like this:
Your collection could look like this:
Graph database
I don't know enough about graph databases to provide much information or ideas here, but I can point to some interesting resources.
LinkedIn have developed their own graph database named LIquid, but I am not sure if they use it for their job search.
Here are a couple of interesting references:
- LinkedIn's Blog article: LIquid: The soul of a new graph database, Part 1
- LinkedIn Principal Staff Engineer Scott Meyer lecture about LIquid
Then of course the most popular graph database is Neo4j. Another popular one is AWS Neptune.
Wrapping up
I've brushed over quite a few things here. For example, LinkedIn also has traditional geospatial / GIS features, such as querying by distance from some point.
I haven't talked at all about how to put together a geographical dataset or about how to wrap all that stuff in an API. Well, I am not writing a book here, just an article, give me a break.
Aside from these intentional omissions, that's pretty much all there is to it. Wrap all that into an API; provide a typeahead dropdown-type component to pick locations; and you're all good to go!
Is there anything you would do differently?